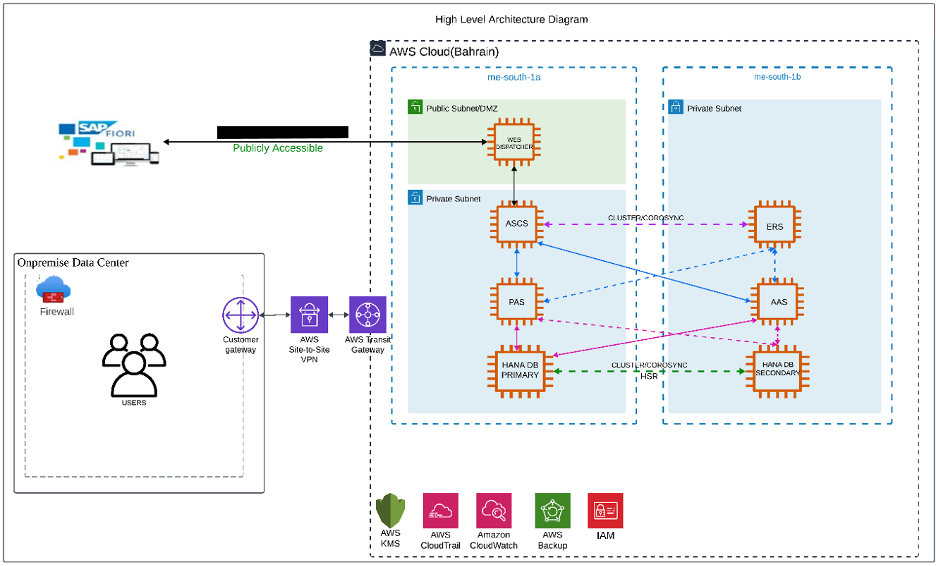
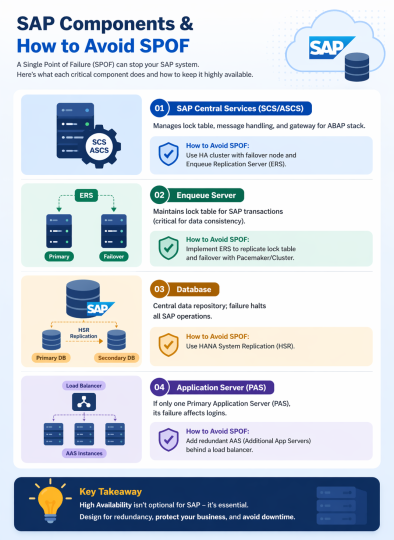
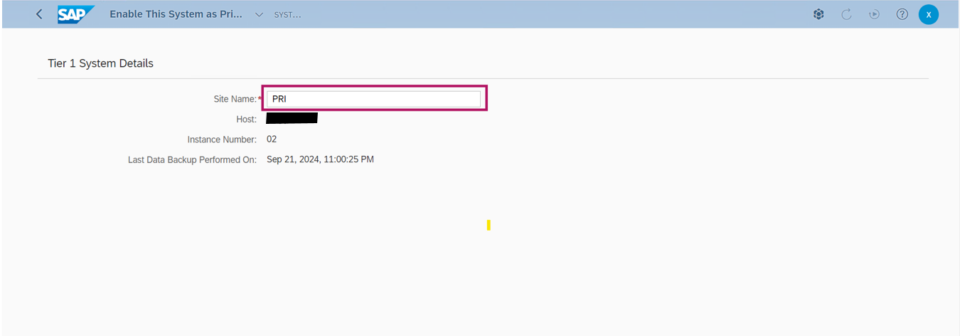
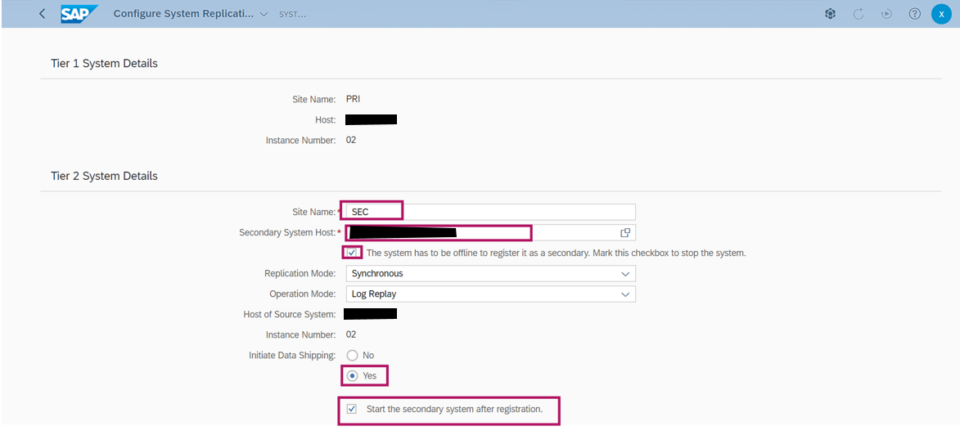
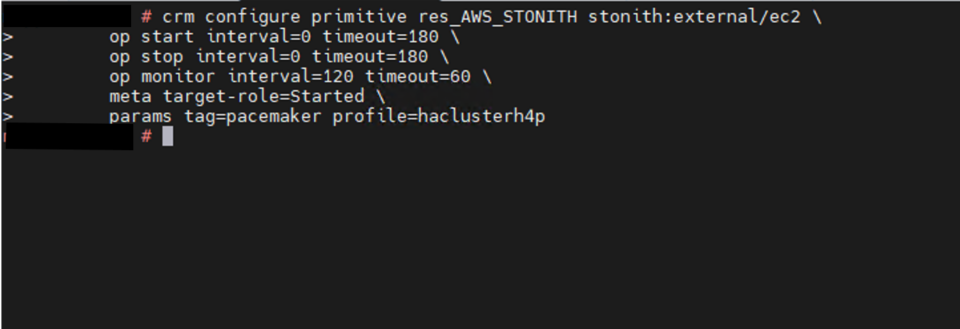
SUSE’s approach automates the takeover process in SAP HANA system replication environments. While replicating data to a secondary SAP HANA instance ensures data availability, it doesn’t guarantee system continuity on its own. To enhance high availability, a cluster solution is required — one that manages the failover process and ensures seamless client access by handling the service address transition.
Cluster Solutions
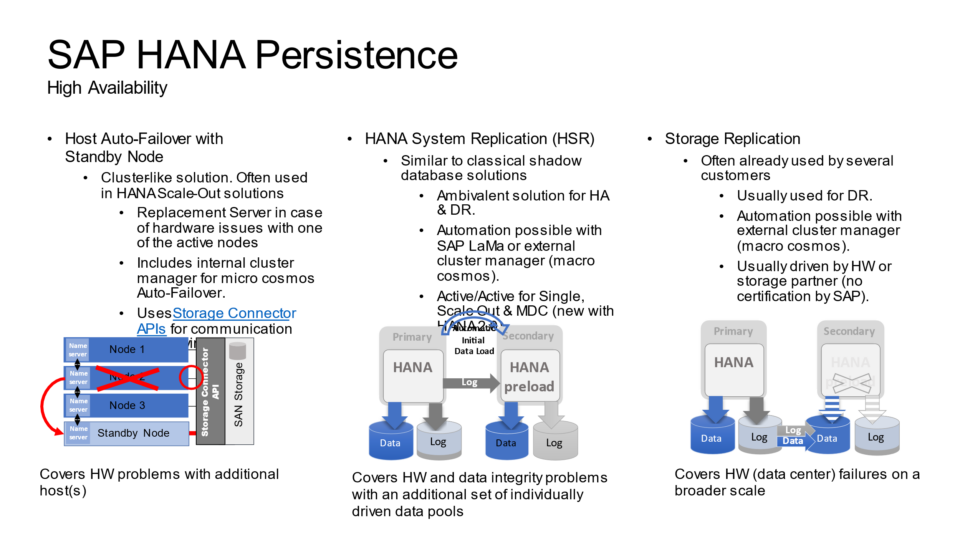
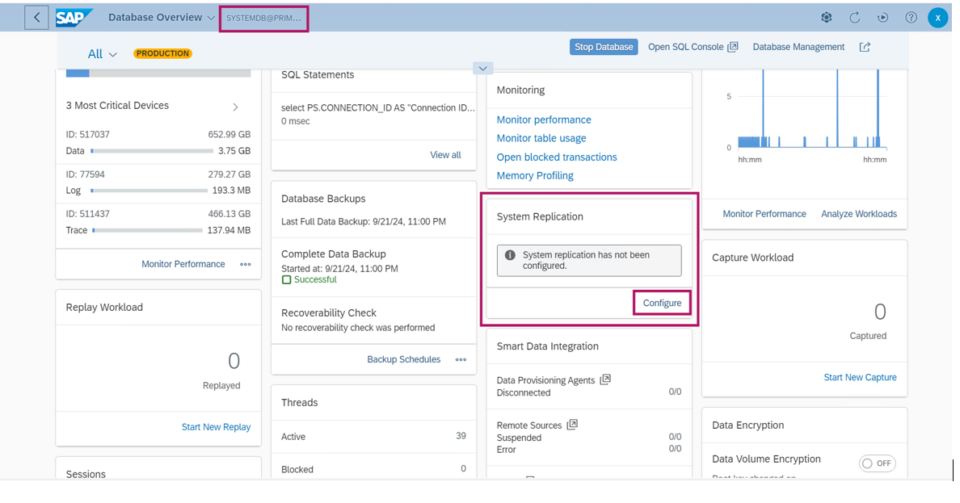
SAP HANA deployments on AWS are architected to provide high availability and fault tolerance at the infrastructure level. However, failures at the SAP HANA database layer still require management. In the event of a hardware or software issue, a manual failover can be initiated using tools such as SAP HANA Cockpit, SAP HANA Studio, or the hdbnsutil command-line utility. These manual recovery procedures may lead to temporary disruptions in business operations.
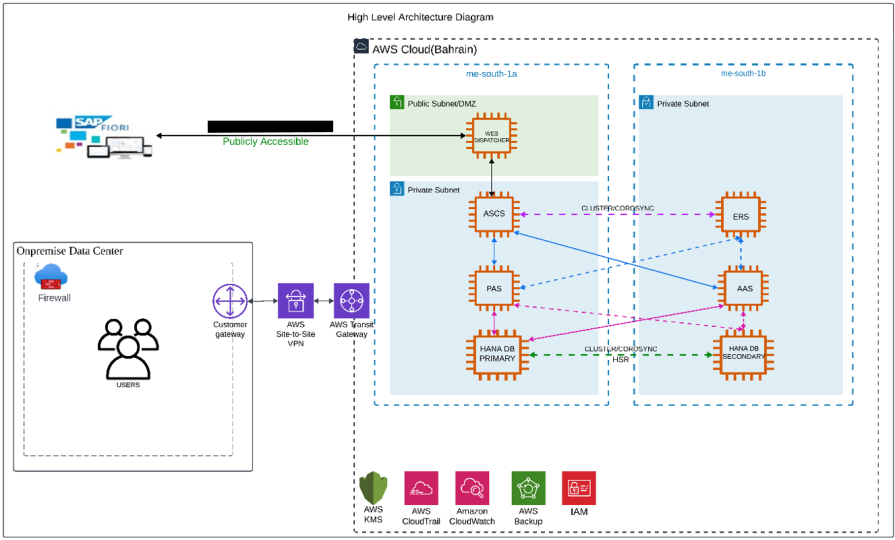
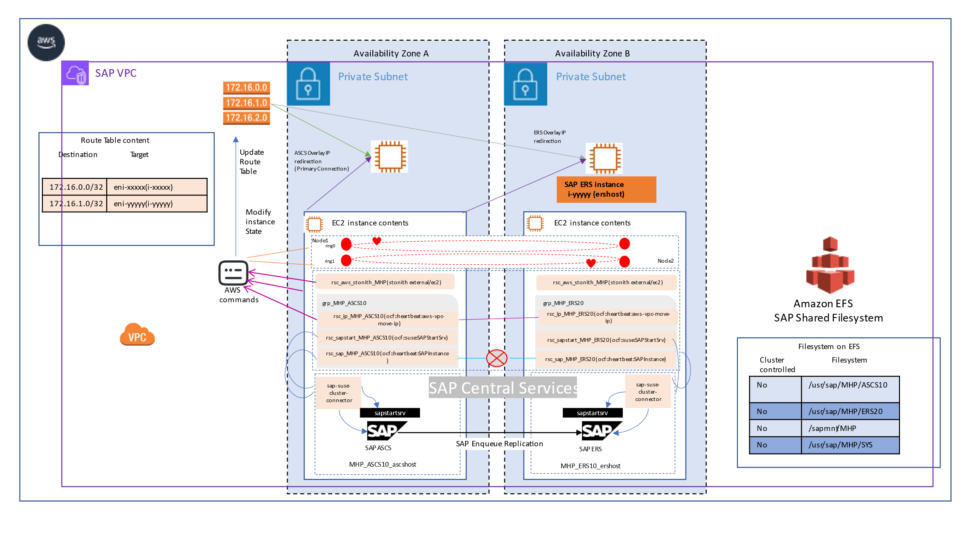
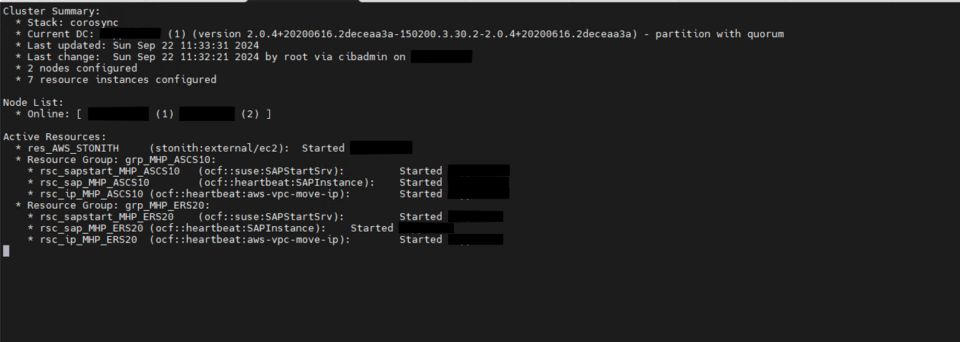
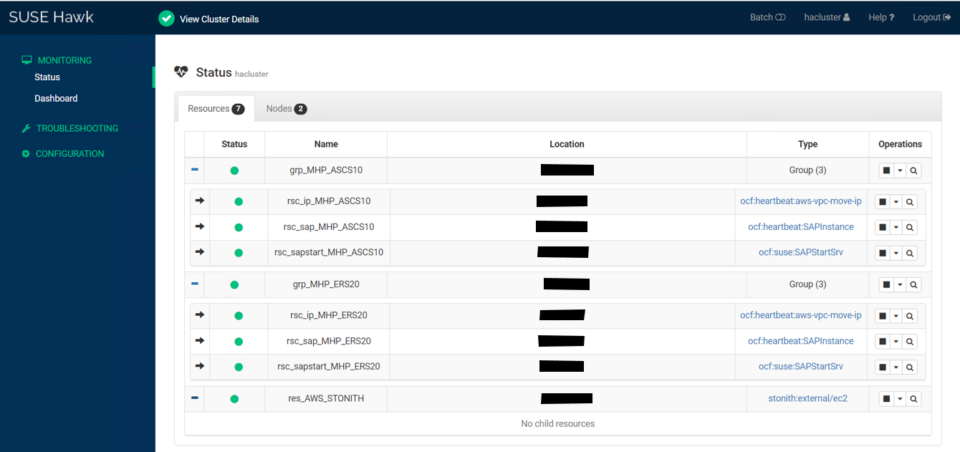
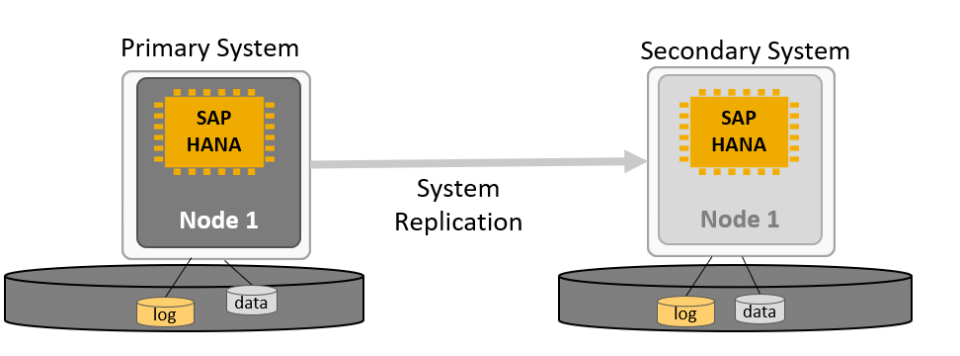
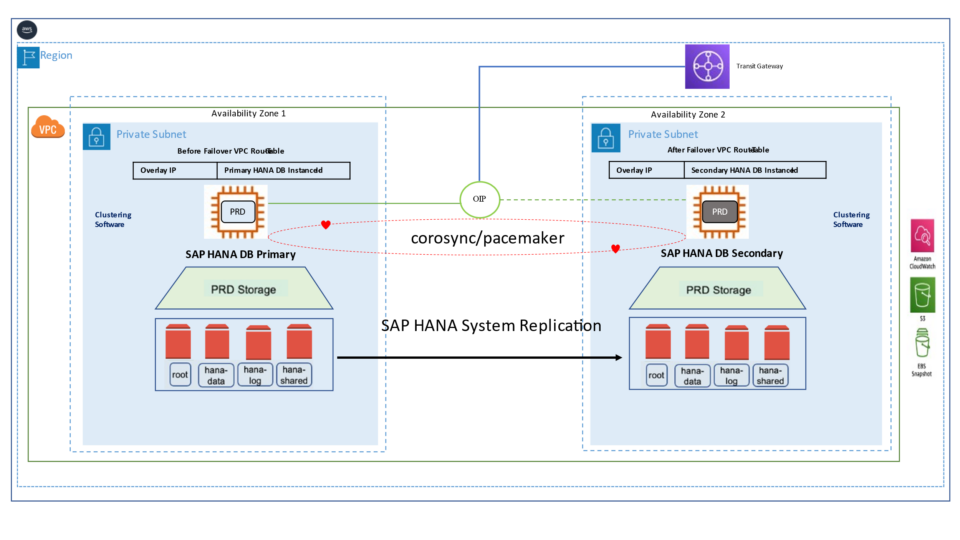
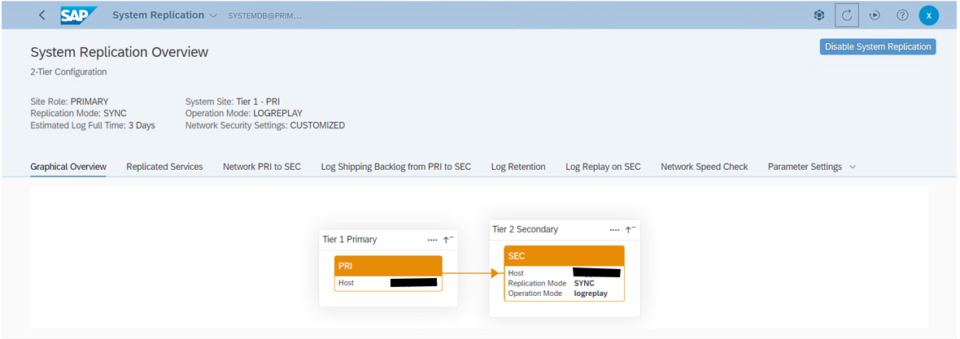
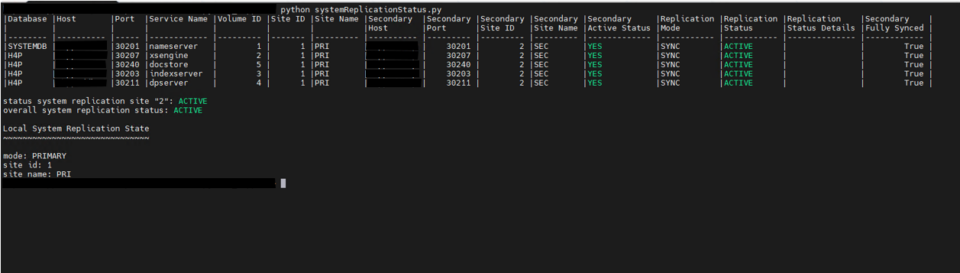
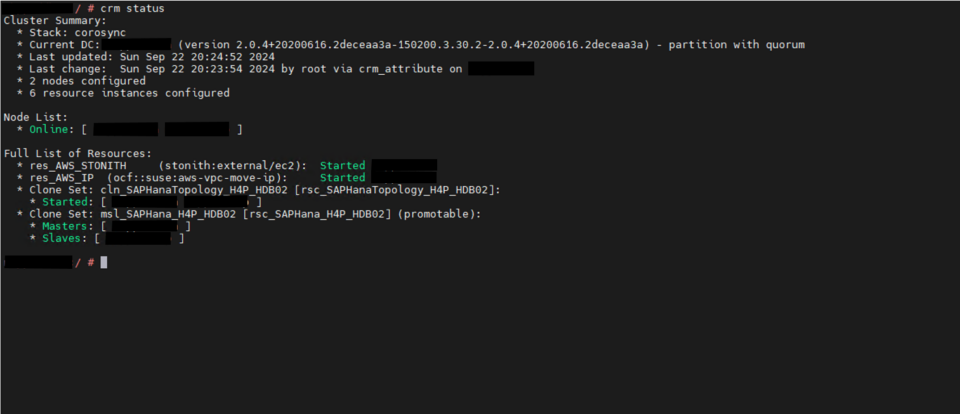
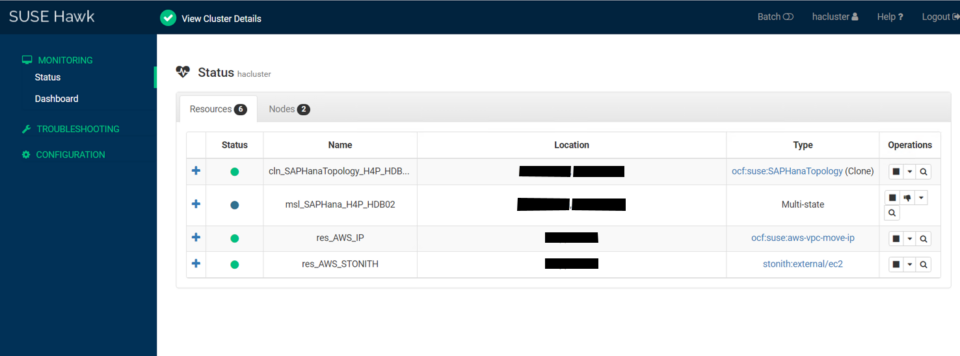
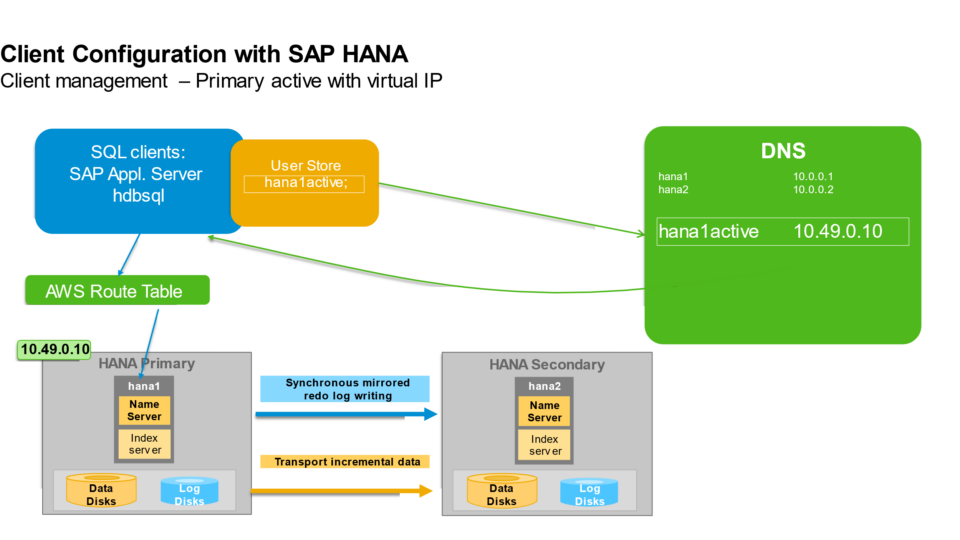
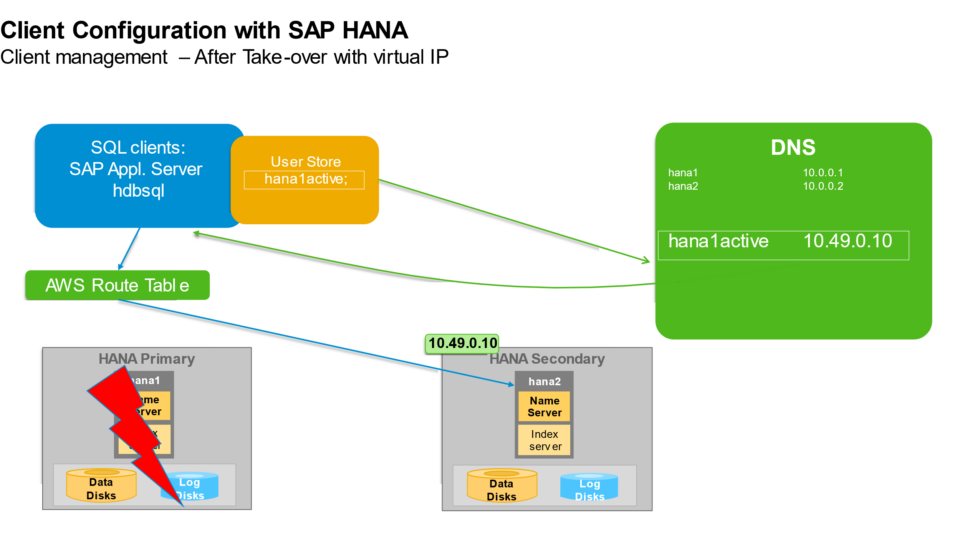
The high availability setup for SAP HANA leveraging System Replication enables automated failover between the primary and secondary instances. Both instances are configured within a Pacemaker cluster, which operates at the OS level and integrates with the SAP HANA database through specialized hooks. This clustering solution continuously monitors the system and initiates automatic failover when needed. As a result, recovery can typically be achieved within minutes or even faster.
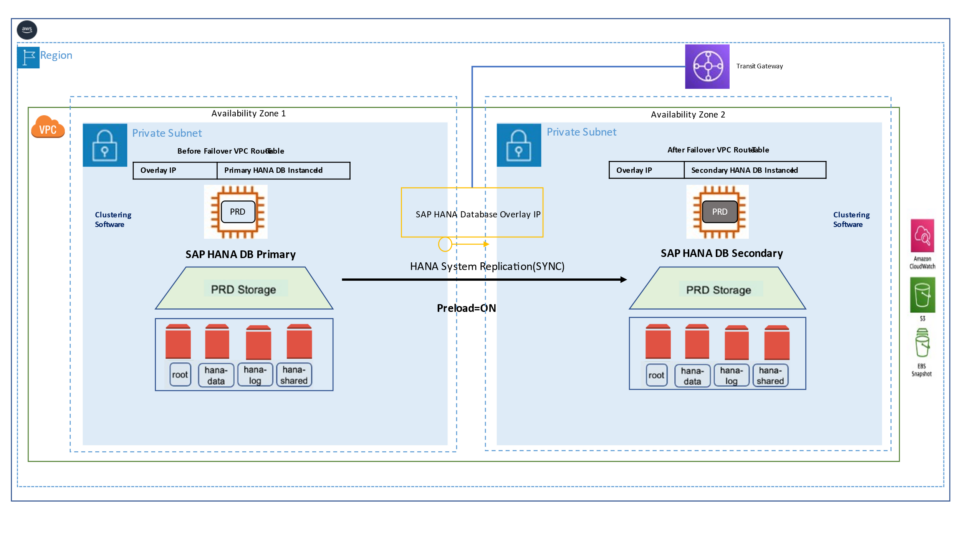
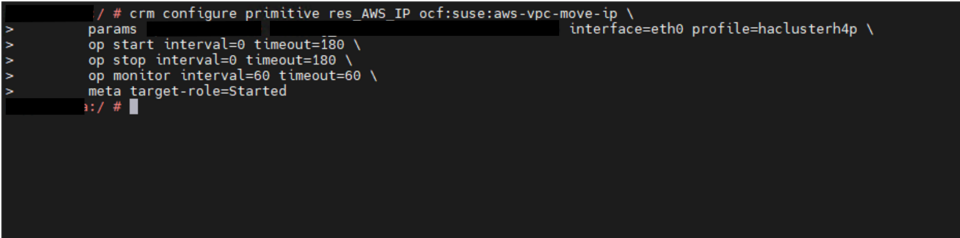
The Pacemaker cluster leverages a virtual IP address to route traffic to the active SAP HANA master instance. During a failover event, this virtual IP is reassigned to the standby instance, which is then promoted to become the new primary. On AWS, an overlay IP address is utilized for network configuration—this virtual IP consistently points to the active SAP HANA node, regardless of whether it resides on the original primary or the secondary system.
Architecture patterns
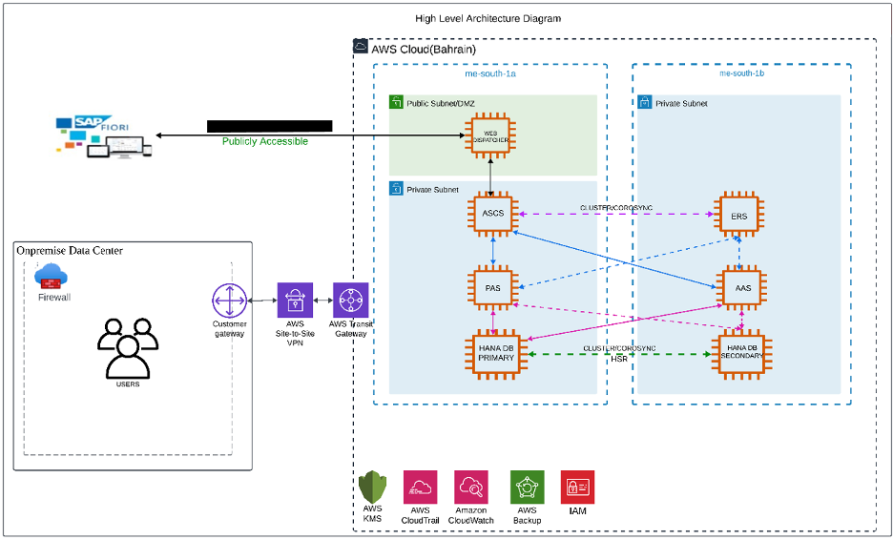
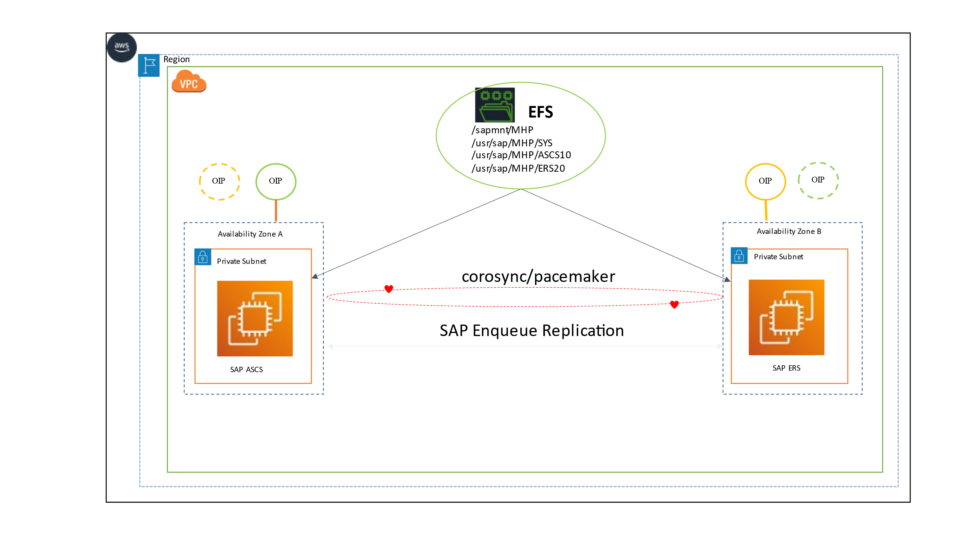
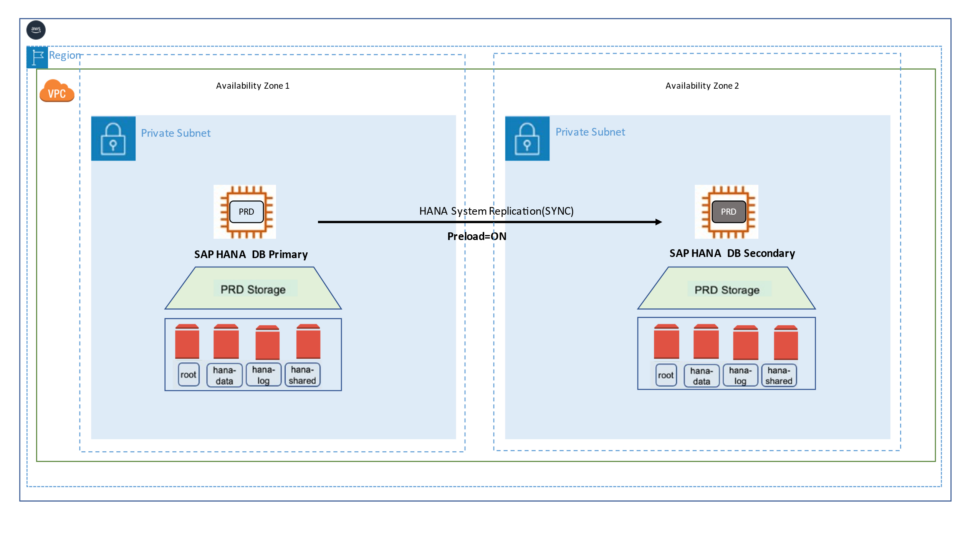
AWS organizes its infrastructure into distinct geographic locations known as regions and subdivides them further into Availability Zones (AZs). Deploying across multiple Availability Zones within a Region enhances fault tolerance and helps maintain consistent performance by reducing the impact of localized failures.
In a single-Region, multi-AZ setup, the secondary SAP HANA system can be deployed in a separate Availability Zone from the primary system within the same Region. This configuration supports fast failover during planned maintenance, storage issues, or localized disruptions, ensuring higher availability and operational continuity.
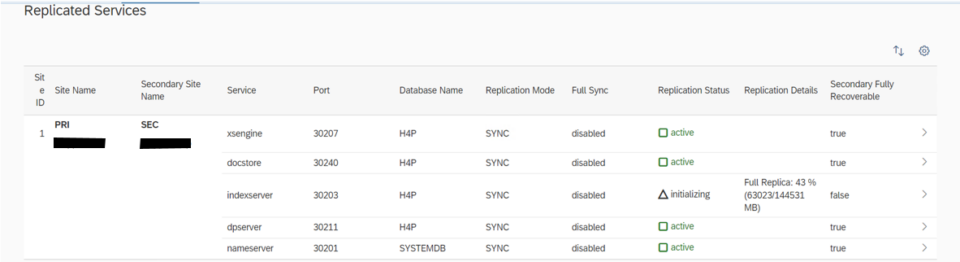
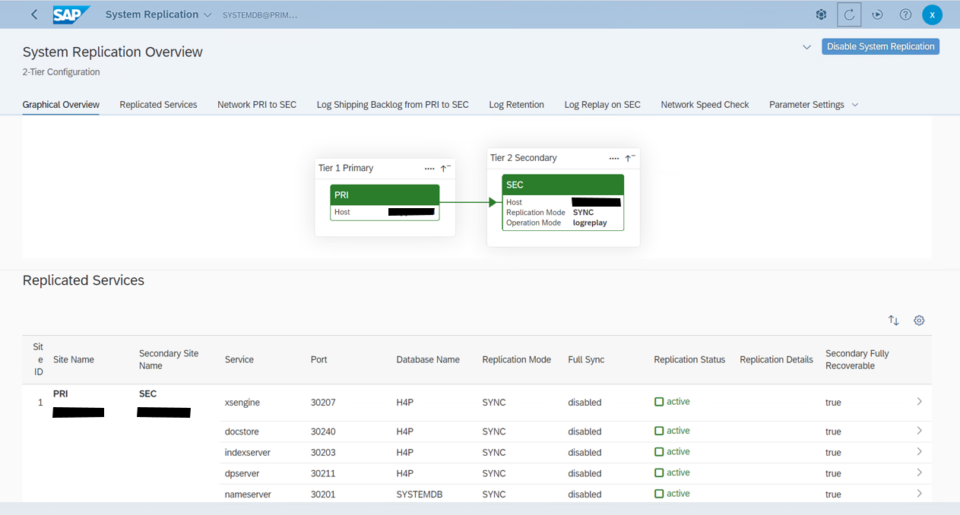
In our project, we have configured Active/Passive secondary system with Performance Optimized Scenario. System replication restricts read access and SQL querying on the secondary system until a takeover occurs, switching the active role from the primary to the secondary system. The secondary functions as a hot standby using the log replay operation mode. In the event of a failure of the primary SAP HANA system on primary node — whether due to a node or database instance issue—the cluster initiates a takeover process. This approach enables the secondary node to utilize pre-loaded data, making takeover significantly faster than a full local restart.
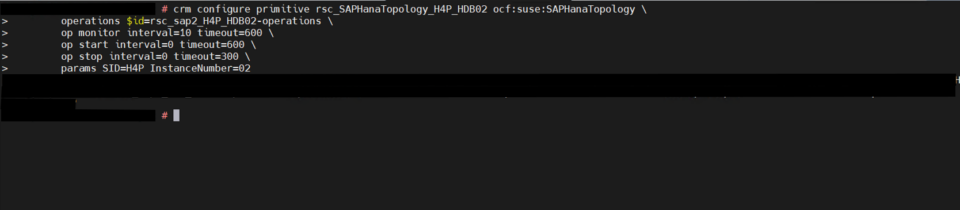
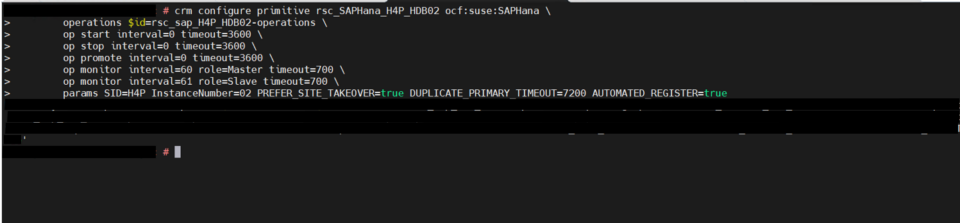
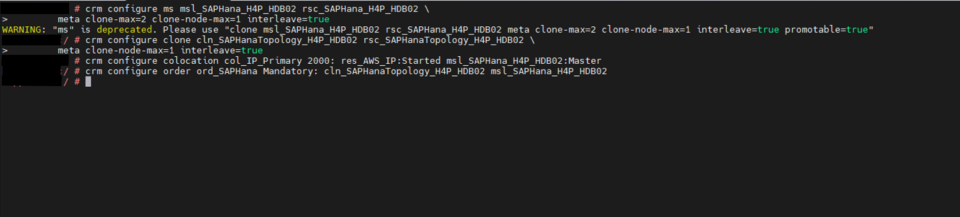
System replication for the production database is managed using the SAP HANA and SAP HANA Topology resource agents. The level of automation can be controlled using the AUTOMATED_REGISTER parameter. When enabled, the cluster automatically registers the former primary node as the new secondary after a failover.